![]()
Одним из двигателей эволюции языка могло быть неравномерное распределение языковых единиц
|
Как в ходе эволюции возник язык? Откуда взялись основные свойства языка — например, высокая регулярность? Один из современных подходов к этим вопросам заключается в том, чтобы искать ответы не только в биологической эволюции человека, но и в эволюции самого языка — то есть изменении его при передаче от поколения к поколению. В рамках такого подхода эффективный способ проверки гипотез — это моделирование языковой эволюции в лаборатории, «на живых людях». Группа ученых из Эдинбурга провела пилотный эксперимент, основной целью которого был поиск условий, необходимых для возникновения регулярности. Эксперимент показал, что регулярные единицы воспроизводятся лучше, чем нерегулярные, только в языках с неравномерным частотным распределением единиц. Таким образом, неравномерность распределения может быть фактором, благоприятствующим возникновению и закреплению регулярности.
Языковая эволюция
Очевидно, что человек смог овладеть языком только потому, что биологическая эволюция наделила его соответствующими возможностями (в первую очередь, мощным мозгом и речевым трактом). Совокупность этих возможностей нередко условно называют «языковым органом» (language module, language faculty). Но что произошло дальше?
Можно предположить, что устройство «языкового органа» полностью предопределяет то, каким должен быть язык. Эта точка зрения лежит в основе генеративной лингвистики (кратко о генеративной лингвистике можно прочесть в новости Язык маленьких детей лучше описывают лексико-специфичные грамматики, а не абстрактные, «Элементы», 06.11.2009).
В последнее время, однако, всё большее влияние приобретает другая гипотеза: «языковой орган» позволил человеку овладеть некоторым «протоязыком», который, предположительно, был примитивнее, чем знакомые нам языки. А дальше началась эволюция самого языка. Передаваясь от поколения к поколению, язык менялся, «стараясь» приспособиться к двум основным требованиями: с одной стороны, стать максимально простым для изучения, а с другой, не потерять выразительности. В сильной форме эта гипотеза гласит, что язык мог возникнуть и приобрести свои основные свойства уже в отсутствие биологической эволюции.
Существенно, что эти две гипотезы не являются полностью взаимоисключающими (соответственно, неверно, что любой исследователь обязательно придерживается только одной и полностью отрицает другую). В частности, не исключено, что языковая эволюция и биологическая эволюция могли идти параллельно, влияя друг на друга.
Языковая эволюция почти не дана нам в непосредственном наблюдении: предполагается, что для современных языков она уже завершилась, поскольку они достигли максимально возможной приспособленности. Сторонники этой гипотезы пытаются использовать данные «новых» языков: контактные языки (пиджины и креолы), спонтанно возникающие жестовые языки (например, никарагуанский жестовый язык), но основным их методом являются эксперименты.
Моделирование языковой эволюции
Если предполагать, что главным критерием приспособленности языка с точки зрения языковой эволюции является его выучиваемость, то есть способность передаваться по наследству, то такую гипотезу можно проверить на несложной модели. Достаточно взять язык (обычно берется маленький искусственный язык из нескольких десятков слов, причем такой, который предположительно будет выучиваться плохо), взять «агента» (либо условного «агента» в компьютерной модели, либо живого человека), заставить его выучить язык, а потом протестировать — насколько он его выучил. После этого можно сравнить язык, существующий в голове у агента (то есть полученные на выходе результаты теста) с изначальным языком (заданным на входе). Различия покажут, как и насколько изменился наш язык за одно поколение (моделью которого является агент). Разумеется, в случае одного-единственного агента возможен какой угодно случайный результат. Однако если такой эксперимент будет проведен много раз и окажется, что некоторые типы изменений происходят всегда или очень часто, а некоторые — никогда или почти никогда, то это уже о чём-то говорит.
Чуть более сложный тип эксперимента, в котором моделируется изменение языка в течение не одного, а многих поколений, — это модель итеративного обучения (iterated learning model). Суть ее в том, что язык, получающийся на выходе у первого агента, подается на вход второму, получающийся на выходе у второго — третьему и так далее. Биологической эволюции при этом не происходит, агенты не меняются, меняется только язык. Если это компьютерный эксперимент, то его можно продолжать до тех пор, пока язык не придет к более или менее стабильному состоянию; если же это эксперимент на живых людях, то, скорее всего, придется остановиться, когда закончатся испытуемые.
Роль компьютерных моделей в изучении языковой эволюции очень велика, но наибольший интерес все-таки вызывают эксперименты на живых людях. Самый известный такой эксперимент был поставлен в 2008 году другой группой ученых из Эдинбурга под руководством Саймона Кирби (см. статьи Cumulative cultural evolution in the laboratory: An experimental approach to the origins of structure in human language и Complex Adaptive Systems and the Origins of Adaptive Structure: What Experiments Can Tell Us, а также краткий популярный пересказ по-русски).
Очень важно понимать, что эксперименты, о которых идет речь, посвящены не изменениям современных языков («современных» в широком смысле: и живых, и мертвых). Они моделируют процесс превращения гипотетического протоязыка в язык современного типа, обладающий привычными нам свойствами. Эксперименты показывают, что изначальный протоязык действительно эволюционирует, и овладевать им становится всё легче. Особенно хорошо это видно в случае итеративного обучения: чем больше номер поколения, тем меньше разница между языком на входе и на выходе. Важнейшее свойство, которое приобретает язык в ходе эволюции и которое и делает его изучение более простым, — это регулярность.
Регулярность и регуляризация
Регулярность возникает, когда одни и те же значения начинают выражаться одинаково. Рассмотрим следующий фрагмент русского языка: стол, дуб, мир, раб. В пределах этого фрагмента число существительного в именительном падеже всегда выражается одинаково: единственное число — отсутствием окончания, множественное — ударным окончанием [ы]. Если добавить слово вор, то регулярность будет уже неполной, потому что во множественном числе ударение будет стоять не на окончании. Ну а если добавить слова стул, рог, сон и бак, то от регулярности уже почти ничего не останется. Если же снять искусственные ограничения и рассмотреть все существительные русского языка, то регулярность в выражении числа, конечно, будет присутствовать (хотя правила, описывающие ее, будут достаточно сложны), но абсолютной она не будет.
В естественных языках регулярность существует почти на всех уровнях (морфология, как в рассмотренным выше примере, синтаксис, семантика и так далее), но притом почти никогда не бывает абсолютной. Почему языки так устроены?
Согласно гипотезе о врожденности языка — потому, что так устроен наш «языковой орган». Согласно гипотезе о языковой эволюции — потому, что регулярные языки лучше приспособлены к передаче по наследству.
В самом деле, регулярность позволяет человеку овладеть всем языком, познакомившись только с его частью (а именно так и происходит изучение языка). Если мы знаем пары стол–столы, дуб–дубы и мир–миры, то мы можем угадать множественное число от слова раб, даже если мы его не знаем.
Эксперименты по моделированию языковой эволюции эту гипотезу подтверждают. Даже если начать эволюцию с абсолютно нерегулярного языка (а вполне вероятно, что протоязык был именно таким), то со сменой поколений он меняется, регуляризуясь и упрощаясь.
Авторы обсуждаемой работы — Эндрю Смит, Барбора Скарабела и Моника Тамарис — изучали три фактора, влияющие на регуляризацию. Первый — степень регулярности языка, подаваемого на вход.
Второй — распределение частотности его единиц. Хорошо известно, что часто встречающиеся слова могут сохранять нерегулярное поведение гораздо дольше, чем редко встречающиеся. Редкие же, наоборот, будут регуляризовываться в первую очередь («Элементы» писали о роли этого эффекта в судьбе английских неправильных глаголов: Лингвистическая эволюция сходна с биологической, 18.10.2007).
Третий — наличие/отсутствие «бутылочного горлышка». «Бутылочным горлышком» (bottleneck) в эволюционных работах называют резкое снижение численности популяции и, соответственно, генофонда (см., например, о бутылочном горлышке в истории человечества: Зарождение человеческой культуры в Африке проходило в два этапа, 05.11.2008). В моделях языковой эволюции этот термин обычно используют, чтобы подчеркнуть, что от поколения к поколению передается не весь язык, а только его часть — как, например, в упомянутом выше эксперименте Кирби. Кирби высказал гипотезу, что наличие бутылочного горлышка может играть ключевую роль в регуляризации: регулярным языкам проще через него проходить.
Эксперимент Смита
Смит и соавторы создали пять типов искусственных языков. В каждом языке было 24 слова для 24 понятий. Понятия были представлены в виде картинок: 12 действий (плакать, танцевать, рисовать и так далее), каждое из которых выполняется людьми разного пола. Типы языков различались степенью регулярности (все языки можно посмотреть здесь).
Полностью нерегулярный язык состоял из 24 разных корней и 24 разных суффиксов, то есть в нём не было никаких закономерностей.
В регулярном на треть языке восемь значений выражалось регулярно: четырьмя корнями — для названий действия и двумя суффиксами — для обозначения пола деятеля (в данном случае можно сказать — грамматического рода); 16 значений выражалось нерегулярно (16 корнями и 16 суффиксами).
В регулярном на половину языке 12 значений выражалось регулярно, а 12 — нерегулярно.
В регулярном на две трети языке 16 значений выражалось регулярно, а 8 — нерегулярно.
В полностью регулярном языке все значения выражались регулярно, то есть в нём было всего 12 корней для названий действий и два суффикса для обозначения рода.
Каждый тип был представлен двумя языками. Конкретные корни и суффиксы в них различались, но структурно языки были идентичны. Главное различие заключалось в частотном распределении: в одном языке все слова встречались одинаково часто, в другом одна половина встречалась в девять раз чаще, чем другая. В естественных языках распределение, разумеется, неравномерное (оно подчиняется закону Ципфа).
Таким образом, всего получилось 10 разных языков. Каждый язык давался четырем участникам. Использовалось не итеративное обучение, а простое: участнику 10 раз поочередно показывали все картинки и называющие их слова (см. главную иллюстрацию). Потом участников тестировали: показывали картинки и просили ввести соответствующие слова.
Существенно, что каждый участник получал на вход весь язык и не должен был придумывать слов для неизвестных ему понятий — то есть бутылочное горлышко, в отличие от многих других экспериментов, отсутствовало.
Предельно обобщая, можно сказать, что авторы пытались ответить на следующие вопросы: мог ли нерегулярный протоязык «сам собой» превратиться в регулярный язык в отсутствие бутылочного горлышка? Какие факторы влияли на регуляризацию? Еще раз подчеркнем, что эксперимент не был посвящен процессам, происходящим в современных языках.
Результаты и выводы
Исследователи проанализировали, насколько хорошо воспроизводились языки разных типов, а также как они изменялись.
|
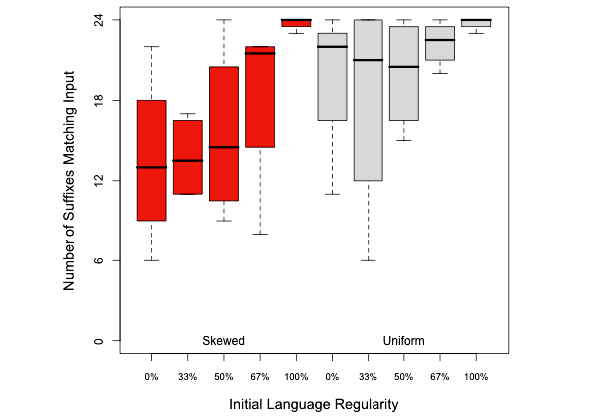
Воспроизводимость
Анализ показал, что в языках с равномерным распределением и корни, и суффиксы воспроизводились лучше, чем в неравномерных языках, однако регулярность не влияла на то, насколько воспроизводился корень или суффикс.
В языках с неравномерным распределением, однако, регулярные суффиксы воспроизводились лучше нерегулярных, а частотные — лучше редких. Ситуация с корнями несколько отличалась: частотные корни воспроизводились лучше редких, но регулярные и нерегулярные воспроизводились одинаково.
Логично предположить, что причина в структуре языков: разница между частотой встречаемости регулярного и нерегулярного корня значительно меньше, чем разница между частотой встречаемости регулярного и нерегулярного суффикса. Нерегулярный корень встречается в одном слове, регулярный — в двух, нерегулярный суффикс встречается в одном слове, регулярный — минимум в четырех, максимум в 12. Естественно, что регулярность будет иметь большее значение для суффиксов, и если что-нибудь и будет подвергаться регуляризации, то в первую очередь именно они.
|
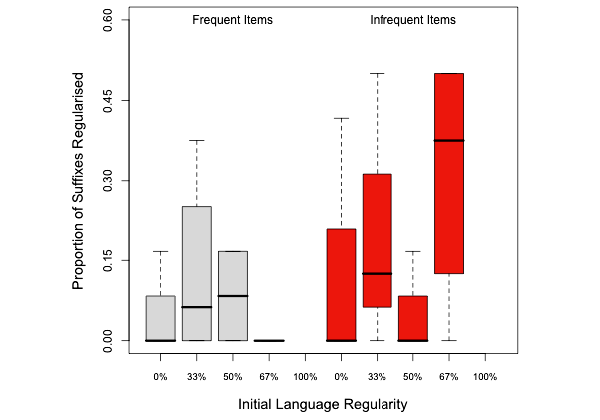
Регуляризация
Считалось, что изначально иррегулярный (то есть встречающийся лишь в одном слове входного языка) суффикс подвергался регуляризации, если в выходном языке ему соответствовал суффикс, который встречался в нескольких словах и выражал один и тот же грамматический род. Такой эффект действительно наблюдался.
Происхождение такого регуляризованного суффикса могло быть различным: это мог быть изначально регулярный суффикс, который стал употребляться с еще одним или несколькими словами (таких случаев было девять); это мог быть изначально иррегулярный суффикс, который стал употребляться с еще одним или несколькими словами и тем самым стал регулярным (20 случаев); наконец, это мог быть новый суффикс, который сразу стал употребляться с двумя или более словами (13 случаев).
Вопреки предсказаниям авторов о том, что в неравномерных языках регуляризация будет происходить чаще, этот эффект не оказался статистически значимым. Не зависела регуляризация и от степени регулярности входного языка.
Единственный статистически значимый эффект, который удалось обнаружить, заключался в следующем: в неравномерном языке, регулярном на две трети (то есть максимально регулярном из рассматриваемых: в полностью регулярном регуляризация, разумеется, происходить не может), редкие нерегулярные суффиксы регуляризовывались чаще, чем частотные нерегулярные.
В неравномерных языках в целом редкие суффиксы тоже регуляризовывались чаще, чем частотные, но до статистической значимости этому эффекту чуть-чуть не хватило. Это вполне может объясняться малым числом подопытных: если эффект есть, то при увеличении выборки он будет обнаружен.
Выводы
Эксперимент показал, что регуляризация может происходить и в отсутствие явного бутылочного горлышка. Авторы предполагают, что низкая частотность редких суффиксов в неравномерных языков приводит к тому, что их трудно выучить, и, соответственно, играет роль неявного бутылочного горлышка: чтобы его проскочить, суффиксам «приходится» приспосабливаться.
Авторам также удалось подтвердить, что неравномерные языки (которые лучше моделируют естественный язык) выучиваются хуже равномерных, а в неравномерных нерегулярные единицы — хуже, чем регулярные. Это может приводить к тому, что именно в неравномерных языках будет происходить регуляризация.
Однако убедительно доказать эту гипотезу авторы не смогли. Тем не менее обнаруженные эффекты указывают на то, что это вполне может быть так и что, увеличив количество испытуемых, можно надеяться получить более ясный ответ.
Таким образом, работа выполняет роль пилотного исследования — шага от несложных, но не очень убедительных компьютерных моделей, к более впечатляющим, но трудоемким экспериментам на живых людях.
Источник: Andrew D. M. Smith, Barbora Skarabela, Monica Tamariz. Exploring the nature of a systematicity bias: an experimental study // The Evolution of Language (EVOLANG 8): Proceedings of the 8th International Conference on the Evolution of Language, pp. 289–296 (электронная версия, PDF, 177 Кб).
См. также:
Лингвистическая эволюция сходна с биологической, «Элементы», 18.10.2007.
Александр Бердичевский
![]()